


随着大数据时代的到来,推荐系统成为个性化服务的核心,从亚马逊淘宝等电商,到豆瓣的电影图书,再到各个音乐播放器,推荐系统都是其业务的重要支撑。为了更好的服务我们的用户,笔者设计并实现了文章推荐系统,来帮助公司挖掘用户历史数据的价值,为用户推荐他们更可能感兴趣的内容,以此增加用户粘性,实现双赢。
文章推荐系统主要以下这几个模块,数据存储、推荐引擎、前端交互模块组成。其中数据存储模块针对不同业务模型混用多种存储技术,包括 MySQL、Redis 和 HDFS;推荐引擎为推荐系统的核心,根据推荐算法主要分为两大模块,文本聚类推荐模块和协同过滤推荐模块,其中文本聚类推荐模块下分别实现了 LDA 和 LSA 两种算法,协同过滤推荐模块下分别实现了基于物品的协同过滤和基于用户的协同过滤两种算法,并利用
Spark 框架对推荐算法进行了优化 。推荐系统首先借助已有的用户数据,在后台通过丰富的推荐算法分析出用户的兴趣偏好,从海量的科技新闻中筛选出其最可能感兴趣的咨询进行推送。笔者参与完成了推荐系统的需求分析和架构设计,参与完成了数据存储模块,并且独立完成了推荐引擎模块。

关键词:推荐系统,协同过滤,文本聚类,SVD,Spark
ABSTRACT
ABSTRACT:
With the development of big data technology, the recommendation system plays a more and more important role in offering personalized service. For example, from Amazon to Taobao, from Douban movie to Netease music, recommendation system is unreplaceable in their business. So for offering our user better service, I design and implement an article recommendation system which can recommend articles they like according to their history records.
The article recommendation system consists of three modules, data storage, recommendation engine, and front end. The data storage module mix a variety of storage technologies, including MySQL and HDFS according to different business models. And the recommendation engine module, as the core module, is separated into two sub-modules, the text clustering model and collaborative filtering model. The text clustering model consists of LDA model and LSA model and the collaborative filtering module consists of item-based collaborative filtering algorithm and user-based collaborative filtering algorithm. The recommendation system will analyze the history data of users and use recommendation engine to find out the preference of users, and then recommend articles they may like. During the project I participated in the design of the system architecture and data storage module, and I finished recommendation engine module on my own.
KEYWORDS:Recommendation System, Collaborative Filtering, Text Clustering, SVD, Spark
目 录
中文摘要 I
ABSTRACT II
目 录 III
1引言 1
1.1 项目的背景和意义 ................................................. 1
1.2 国内外研究现状 ................................................... 1
1.4 项目难点与特色 ................................................... 2
1.4.1 项目难点 ..................................................... 2
1.4.2 项目特点 ..................................................... 2
1.5 作者的主要工作 ................................................... 2
1.6 论文的组织结构 ................................................... 2
1.7 本章小结 ......................................................... 3
2相关技术介绍 4
2.1 FLASK ............................................................... 4
2.2 SPARK ............................................................... 4
2.3 HDFS ............................................................... 5
2.4 结巴分词 ......................................................... 6
2.5 本章小结 ......................................................... 6
3推荐算法介绍 7
3.1 基于协同过滤的推荐 ............................................... 7
3.1.1 矩阵分解 ..................................................... 7
3.1.2 基于物品的矩阵补全 ........................................... 8
3.1.3 基于用户的矩阵补全 ........................................... 8
3.1.4 相似度计算 ................................................... 9
3.2 基于文本聚类的推荐 .............................................. 10
3.2.1 词袋模型 .................................................... 10
3.2.2 TF-IDF ...................................................... 10
3.2.3 LSA 模型 ..................................................... 12
3.2.4 LDA 模型 ..................................................... 12
3.3 本章小结 ........................................................ 13
4系统需求分析 14
4.1 功能性需求 ...................................................... 14
4.1.1 文章推荐系统整体功能性需求 .................................. 14
4.1.2 推荐引擎模块功能性需求 ...................................... 15
4.1.2.1 基于文本聚类的推荐功能性需求 ............................... 15
4.1.2.2 基于协同过滤的推荐功能性需求 ............................... 16
4.1.3 数据存储模块功能性需求 ...................................... 16
4.1.4 前端交互模块功能性需求 ...................................... 17
4.2 非功能性需求 .................................................... 17
4.3 本章小结 ........................................................ 18
5系统概要设计 19
5.1 文章推荐系统架构设计 ............................................ 19
5.2 数据库设计 ...................................................... 20
5.2.1 MySQL ....................................................... 20
5.2.2 HDFS ........................................................ 22
5.2.3 Redis ....................................................... 22
5.3 本章小结 ........................................................ 22
6系统详细设计与实现 23
6.1 协同过滤推荐模块 ................................................ 23
6.1.1 流程设计 .................................................... 23
6.1.2 类图设计 .................................................... 25
6.1.3 模块实现 .................................................... 26
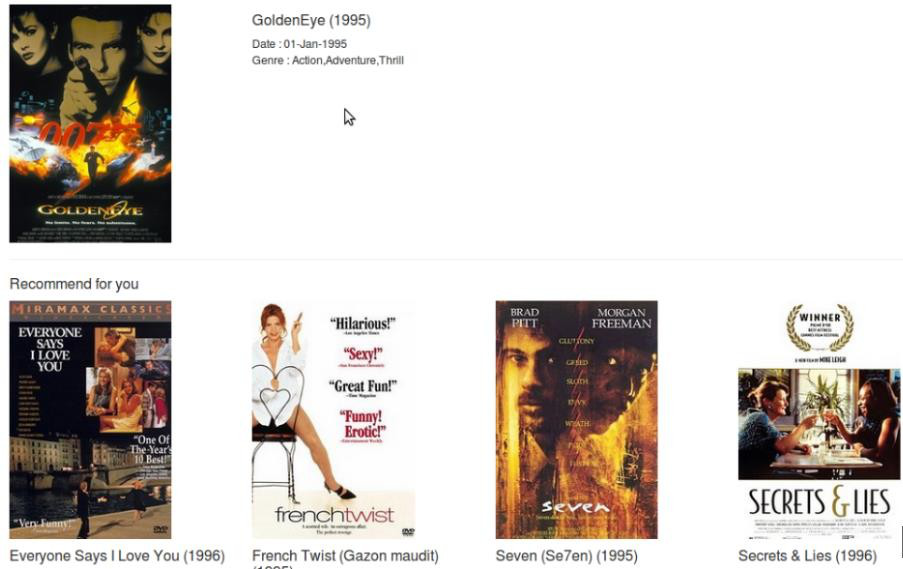
6.1.4 文章推荐截图展示 ............................................ 28
6.2 文本聚类推荐模块 ................................................ 29
6.2.1 流程设计 .................................................... 29
6.2.2 类图设计 .................................................... 30
6.2.3 模块实现 .................................................... 32
6.2.4 文章推荐截图展示 ............................................ 32
6.3 数据存储模块详细设计与实现 ...................................... 33
6.3.1 MySQL ....................................................... 33
6.3.2 HDFS ........................................................ 35
6.3.3 Redis ....................................................... 35
6.4 本章小结 ........................................................ 35
7推荐效果展示与分析 37
7.1 LSA 模型 .......................................................... 37
7.1.1 推荐结果展示 ................................................ 37
7.1.2 推荐结果分析 ................................................ 38
7.2 LDA 模型 .......................................................... 39
7.2.1 推荐结果展示 ................................................ 39
7.2.2 推荐结果分析 ................................................ 40
7.3 LSA、LDA 推荐效果比较 ............................................. 40
7.4 基于物品的协同过滤 .............................................. 41
7.4.1 推荐结果展示 ................................................ 41
7.4.2 推荐结果分析 ................................................ 41
7.5 基于用户的协同过滤 .............................................. 42
7.5.1 推荐结果展示 ................................................ 42
7.5.2 推荐结果分析 ................................................ 43
7.6 基于用户、基于物品协同过滤比较 .................................. 44
7.7 本章小结 ........................................................ 45
8系统测试 46
8.1 功能性测试 ...................................................... 46
8.2 性能效果测试 .................................................... 46
8.3 本章小结 ........................................................ 47
9总结展望 48
参考文献 49
致 谢 50
附 录 51
1引言
本章为引言部分,将介绍文章推荐系统项目的背景和意义,国内外研究现状,以及本人的工作,同时将介绍论文的组织结构。
1.1项目的背景和意义
信息技术蓬勃发展了半个多世纪,全球各地每天都有数以亿计的用户活跃在各种互联网平台,他们的行为会产生海量的数据,其中相当一部分数据对用户来讲是无效的。用户使用互联网产品的时间是有限的,互联网服务提供商要充分利用这段时间实现自身利益的最大化。在这种情况下,电商要考虑如何利用用户的历史数据为用户筛选出他们最可能感兴趣的商品以卖出更多商品,社交网络要考虑如何为用户推荐他们感兴趣的账号以激发用户活跃度,电影音乐网站要考虑如何为用户推荐他们最可能喜欢的作品以增加用户粘性,他们共同需要的一项工具就是推荐系统。
而笔者的毕设项目,文章推荐系统,也是其中一种。该系统通过挖掘文章本身主题特征,以及分析用户历史数据,分析出用户对咨询文章的偏好,然后进行有针对性的文章推荐,以此来优化用户体验,在增加自身文章阅读量的同时培养用户忠诚度。
1.2国内外研究现状
推荐系统的技术主要分三大类,基于人口统计、基于物品内容、以及基于协同过滤的推荐技术。基于人口统计的推荐技术利用用户的个人资料以及用户之间的好友关系进行兴趣挖掘,内容推荐,比如新浪微博的好友推荐。基于物品内容的推荐技术可细分为基于元数据的推荐,比如根据电影的导演,演员进行推荐,和基于内容数据的推荐,比如音乐播放器对音乐的个性化推荐。
第三种推荐技术协同过滤是十分流行的一种策略,之所以被广泛使用有以下几方面原因:(1) 协同过滤问题的模型所需要的信息简介,只需要一个评分矩阵,而不需要用户信息和物品信息。(2) 协同过滤问题本质上是矩阵补全问题,而这一问题是一个经典的机器学习问题,近些年机器学习的发展也促使了协同过滤的流行。
1.4项目难点与特色
本节介绍文章推荐系统项目在设计开发中遇到的的难点,以及该项目的特色
1.4.1项目难点
该项目的难点如下
(1)推荐系统的算法有很多选择,要结合自身业务的特点选择合适的算法。针对 web端的业务,笔者选择了基于内容的推荐技术;针对微信公众号的业务,笔者选择了协同过滤的推荐技术
(2)推荐系统要求实时响应用户需求,但许多推荐模型运行时间较长,无法满足实时要求,需对推荐引擎进行优化
(3)推荐系统要与现有线上系统集成,要避免功能模块之间的耦合,方便后续开发与维护
1.4.2项目特点
该项目的特点如下
(1)混用四种推荐策略,保证推荐效果
(2)采用多种存储技术,包括 MySQL、HDFS、Redis,以保证线上实时推荐的效率
(3)使用 Spark 框架对推荐引擎进行加速
(4)系统采用基于 MVC 架构的 Flask 框架,可扩展性强,鲁棒性强
1.5作者的主要工作
笔者在参与了文章推荐系统的需求分析,架构设计,并独立完成了推荐引擎的核心算法实现,包括基于内容的推荐模块与基于协同过滤的推荐模块。之后将已有工作进一步扩充,完成了数据存储模块,并搭建起 Spark 平台对推荐算法进行优化,此外还完成了 web 端的推荐效果展示模块。
1.6论文的组织结构
本论文一共分为八章,内容安排如下:
第一章介绍文章推荐系统项目的背景和意义,国内外研究现状,以及本人的工作,
同时将介绍论文的组织结构。
第二章介绍毕设中使用到的主要技术,包括 Flask 框架,Jinjia2 模板引擎,Spark 框架和 HDFS 数据库。
第三章介绍了文章推荐系统中所使用的推荐策略,包括基于 LSA 模型的推荐,基于 LDA 模型的推荐,基于物品的协同过滤以及基于用户的协同过滤。
第四章介绍了整个系统的需求分析,包括功能性需求和非功能性需求。第五章介绍了文章推荐系统的概要设计。
第六章介绍了文章推荐系统的详细设计与实现。第七章介绍了文章推荐系统推荐效果的测试。
第八章是总结与展望,说明了文章推荐系统的可改进的方面并对该系统未来的前景进行了展望。
1.7本章小结
本章为引言部分,介绍了项目的背景,项目的意义,项目的难点与特色,以及本人的主要工作,最后还介绍了论文的组织结构。
2相关技术介绍
本章介绍了笔者在文章推荐系统项目中用到的主要的技术,包括 python 框架 Flask,大数据框架 Spark 和 分布式文件系统 HDFS,以及内存数据库 Redis。
2.1Flask
Flask 是一款由 python 语言编写的 web 框架,它使用了 Werkzeug 工具套件。它集成了 Jinja2 模板引擎。Flask 最大的特点是核心小,但可以通过丰富的插件来扩展其功能,如数据库管理,表单验证,文件上传等。在笔者的毕设项目中,主要使用到的插件有 flask-SqlAlchemy, flask-whooshalchemy, sqlalchemy-migrate, 等。
此外 Flask 还具有很多优点。首先 Flask 集成了开发用服务器和错误调试器,方便编程人员在本地测试代码以及及时调试代码。此外 Flask 还有丰富的文档,便于查阅学习。
2.2Spark
Spark 一个十分易用,非常流行的集群计算框架。
Spark 框架具有以下优点:
(1)运行速度快
Spark 支持在内存中对数据进行计算,官方数据表明,对于某些特定算法,如果数据从磁盘读取,Spark 执行速度是 Hadoop MapReduce 模型的 10 倍以上;如果数据从内存读取,Spark 执行速度将是 MapReduce 模型的 100 倍以上。因此 Spark 特别适合于执行一些机器学习算法。
(2)易用性良好
Spark 本身由 Scala 语言编写,这是一种面向对象的函数式编程语言,能够用简介的代码处理复杂的逻辑,减轻编程人员工作量。此外,Spark 还支持通过 Java,Python 等语言编程。
(3)通用性强
Spark 包含了 Spark Core、Spark SQL、Spark Streaming、MLLib 和 GraphX 等一系列实用的组件。Spark Core 提供了内存计算框架,Spark Streaming 支持实时处理应用, Spark SQL 为结构化数据查询提供支持,MLlib 提供了丰富的机器学习算法库,以及
GraphX 补全了 Spark 图像处理的空白。
(4)跨平台运行
Spark 的运行方式非常丰富,既可以简易的以单节点模式运行,又可以在 Hadoop
Yarn 平台,EC2 平台以及 Apache Mesos 平台上运行。Spark 还可以访问任何 Hadoop 数据源,包括 HDFS, Cassandra, HBase, Hive, Tachyon。
2.3HDFS
HDFS 是一个分布式文件系统,用来存储海量数据。它可以在被部署在低成本硬件上的同时满足高容错性。
HDFS 使用 Name Node 对存储进行管理,而真正的数据存储在 Data Node 中。读取数据时,HDFS Client 借助 Distributed File System 与 Name Node 交互,获得所需数据位置,再到对应 Data Node 读取。
图 2-1 HDFS 读取文件
HDFS 写入数据时,HDFS Client 首先与 Name Node 沟通,找到可以使用的 Data
Node,再通过 FSData Output Stream 向 Data Node 写入数据。最后再告知 Name Node 写入信息。
图 2-2 HDFS 写入文件
2.4结巴分词
结巴分词是一个中文分词工具。它支持三种分词模式。第一是精确分词模式,可以将句子精确地分开,适合文本分析。第二种是全模式,可以将句子中所有的可以构成中文词的词语都扫描到,虽然这种模式速度快,但是并不能解决汉语中歧义的问题,如一词多义或者多次一义。第三种是搜索引擎模式,这种模式是对第一种模式的改进。它切分了长度较长的词,以提高召回率,适合用于搜索引擎的分词。
2.5本章小结
本章为相关技术介绍部分,介绍了笔者在文章推荐系统开发中用到的主要技术的特点,包括 python 框架 Flask,大数据框架 Spark 和分布式文件系统 HDFS 等技术。


